Abstract
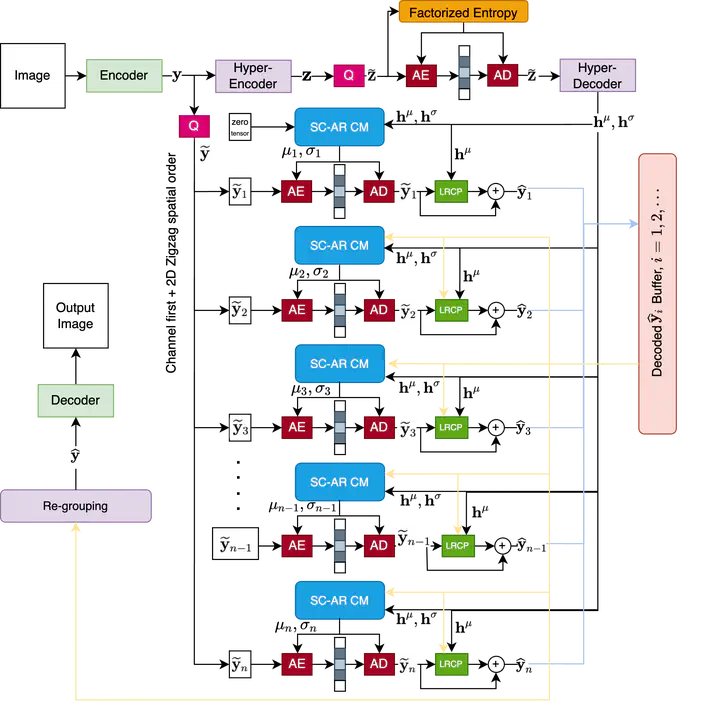
Recent years have witnessed great advances in deep learning-based image compression, also known as learned image compression. An accurate entropy model is essential in learned image compression, since it can compress high-quality images with a lower bit rate. Current learned image compression schemes developed entropy models using context models and hyperpriors. Context models utilize local correlations within latent representations for better probability distribution approximation, while hyperpriors provide side information to estimate distribution parameters. Most recently, several transformer-based learned image compression algorithms have emerged and achieved state-of-the-art rate distortion performances, surpassing existing convolutional neural network (CNN)-based learned image compression and traditional image compression. Transformers are better at modeling long-distance dependencies and extracting global features than CNNs. However, the research of transformer-based image compression is still in its early stage. In this work, we propose a novel transformer-based learned image compression model. It adopts transformer structures in the main image encoder and decoder and in the context model. In particular, we propose a transformer-based spatial-channel auto-regressive context model. Encoded latent-space features are split into spatial-channel chunks, which are entropy encoded sequentially in a channel-first order, followed by a 2D zigzag spatial order, conditioned on previously decoded feature chunks. To reduce the computational complexity, we also adopt a sliding window to restrict the number of chunks participating in the entropy model. Experimental studies on public image compression datasets demonstrate that our proposed transformer-based learned image codec outperforms traditional image compression and existing learned image compression models visually and quantitatively.